
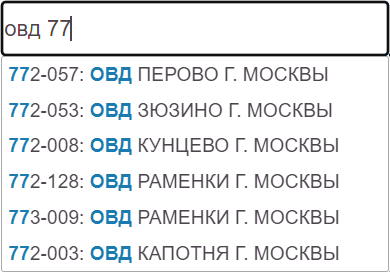
 Ранее в этом году мы добавили на Ахантере функции автодополнения для быстрого заполнения банковских реквизитов, о чём рассказали в наших новостях. Сейчас возможности нашего сервиса пополнились ещё одной функцией из данной категории, а именно - подсказками для некоторых полей паспортных данных. Речь идёт о полях "Код подразделения" и "Кем выдан паспорт". Эти поля не содержат персональных данных, однако часто их заполнение требуется наравне с основными паспортными данными, такими как серия и номер паспорта, дата выдачи, место регистрации и пр.
Ранее в этом году мы добавили на Ахантере функции автодополнения для быстрого заполнения банковских реквизитов, о чём рассказали в наших новостях. Сейчас возможности нашего сервиса пополнились ещё одной функцией из данной категории, а именно - подсказками для некоторых полей паспортных данных. Речь идёт о полях "Код подразделения" и "Кем выдан паспорт". Эти поля не содержат персональных данных, однако часто их заполнение требуется наравне с основными паспортными данными, такими как серия и номер паспорта, дата выдачи, место регистрации и пр.
Обычно поле "Кем выдан паспорт" содержит название отделения МВД или паспортного стола Федеральной миграционной службы конкретного населённого пункта, в котором был выдан паспорт. При этом поле "Код подразделения" содержит числовой код этого отделения. Получается, что оба эти поля взаимосвязаны, так что заполнение одного из них должно приводить к автоматическому заполнению второго. Однако, при заполнении этих полей вручную можно ошибиться в конкретных словах названия подразделения, но, хуже всего, если будет допущена опечатка в коде подразделения. Это приведёт к рассогласованию обоих полей, поскольку опечатка в коде даст подразделение, не соответствующее введённому названию.
Для предотвращения таких ошибок мы сделали функцию подсказок по подразделениям ФМС. Она позволяет по фрагменту кода подразделения, его адреса или названия найти и выбрать именно то подразделение, которое выдало паспорт, после чего автоматически заполнить поля "Код подразделения" и "Кем выдан паспорт". Чаще всего данную функцию используют для поиска подразделения по его коду. Это оказывается удобным, поскольку достаточно ввести код, чтобы автоматически заполнить длинное название соответствующего подразделения. Ну, а если код введён некорректно, то пользователь видит другое название, не соответствующее его паспорту, и это заставляет внести исправления и получить нужное название.
Для разработки такой функции мы собрали из открытых источников информацию о подразделениях ФМС, причём некоторые из них содержат исторические сведения о паспортных столах, которые сейчас уже отсутствуют либо переименованы. Мы осознанно сохранили эти данные, чтобы с помощью нашего сервиса получать подсказки при вводе как новых, так и давно выданных паспортов.
Всю эту информацию мы объединили, устранили дубли, опечатки и неточности, а также применили наши методы по обработке текстовых данных, чтобы получить для каждого подразделения названия в именительном и творительном падежах. Именительный падеж используется, когда заполняемое поле паспорта отвечает на вопрос "Кто выдал паспорт", а творительный падеж отвечает на вопрос "Кем выдан паспорт". Для этих целей мы использовали наш обучаемый морфологический анализатор, описание работы которого можно найти в наших публикациях здесь.
Новый функционал мы добавили в разделе Демо, а также включили в API в рамках функции suggest/fms, документация на которую доступна здесь. В зависимости от конкретной задачи с помощью этой функции можно запрашивать у сервиса и предлагать пользователю подсказки для названий подразделений ФМС как в именительном, так и в творительном падеже, а также получать их коды.
Наш сервис ahunter.ru преодолел очередной значимый рубеж. На данный момент количество данных, которое обработал сервис, достигло двух миллиардов. Это суммарные данные, полученные сервисом как через API, так и путём пакетной обработки файлов. Вот так сейчас выглядит распределение используемых возможностей сервиса среди наших пользователей.
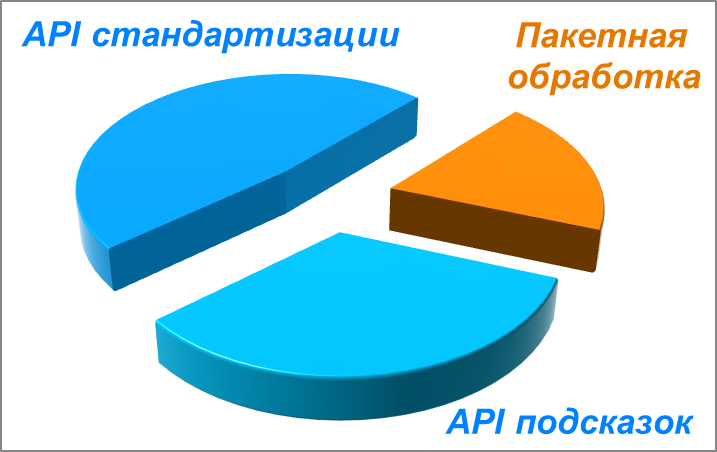
Предыдущая веха в 1 миллиард была достигнута 3 года назад – в мае 2021 года. Надо отметить, что первый миллиард с момента запуска сервиса был обработан за 12 лет. Благодаря непрерывной и кропотливой работе над улучшением и расширением функционала сервиса, на обработку второго миллиарда потребовалось гораздо меньше времени. Это связано в первую очередь с расширением возможностей сервиса и, как следствие, с ростом интереса к сервису со стороны бизнеса и государственных структур. Этому способствовала, в частности, регистрация Ахантера в реестре отечественного ПО.
Вследствие роста нагрузки на сервис за последние три года нам пришлось расширять и оптимизировать его инфраструктуру. За этот период сервис дважды переезжал на новые, более мощные, серверы. Сейчас сервис в среднем обрабатывает ~1 миллион запросов ежедневно. В периоды пиковой нагрузки количество запросов в секунду достигает 500 штук.
За прошедшие 3 года на сервисе была внедрена возможность стандартизации адресов Казахстана и вместе с ней - функции подсказок по адресам этой страны. К ним был добавлен гео-кодер по Казахстану, который позволил получать координаты казахских адресов и наоборот – получать адреса Казахстана по их координатам. Кроме этого мы научили наш сервис точно проверять существование квартир в заданных адресах по государственному адресному реестру, выполнять поиск адресов по кодам ФИАС и получать кадастровые номера адресов.
В связи с появлением в России новых регионов, на нашем сервисе была добавлена возможность выполнять стандартизацию и гео-кодирование адресов с территорий Херсонской и Запорожской областей, а также с территорий ДНР и ЛНР. Ещё, недавно мы внедрили функцию подсказок по банкам, которая позволяет получать платёжные реквизиты банка по его названию или БИК-коду.
Сейчас перед нашей командой стоят новые научно-исследовательские задачи, решение которых, как это обычно бывает, получит своё отражение и в новых возможностях сервиса.
 У Ахантера есть несколько функций автодополнения, позволяющих организовать быстрый ввод контактных данных людей или компаний. Кроме контактных данных для организаций и ИП на нашем сервисе доступны функции подсказок, позволяющие быстро получать реквизиты юридических лиц и индивидуальных предпринимателей. Эти функции нужны, чтобы упростить заполнение громоздких форм с реквизитами компаний и снизить процент ошибок, непременно возникающих при ручном вводе этих данных. В дополнение к этой возможности мы разработали похожий функционал для получения платёжных реквизитов банков.
У Ахантера есть несколько функций автодополнения, позволяющих организовать быстрый ввод контактных данных людей или компаний. Кроме контактных данных для организаций и ИП на нашем сервисе доступны функции подсказок, позволяющие быстро получать реквизиты юридических лиц и индивидуальных предпринимателей. Эти функции нужны, чтобы упростить заполнение громоздких форм с реквизитами компаний и снизить процент ошибок, непременно возникающих при ручном вводе этих данных. В дополнение к этой возможности мы разработали похожий функционал для получения платёжных реквизитов банков.
Этот функционал позволяет выполнять поиск именно кредитных организаций (включая банки) по дополнительным параметрам, таким как коды БИК и СВИФТ. Поиск по фрагменту названия банка, его адресу, кодам ОГРН и ИНН также доступен в новом функционале, однако чаще всего востребована именно возможность получить по коду БИК сведения о банке, например, чтобы ускорить заполнение платёжного поручения, в котором необходимо указывать реквизиты банка получателя платежа.
Важными данными, которые наш сервис возвращает для подсказываемого банка, являются номера его корреспондентских счетов. Чаще при ручном вводе ошибки возникают именно в номере счёта, т.к. такой номер содержит много разрядов, в которых легко запутаться. С помощью наших подсказок эти данные не надо вводить вручную, они автоматически подтягиваются из базы сервиса, которую мы собираем на основе БИК-справочника Банка России, а также на основе книги государственной регистрации кредитных организаций. Кроме этого сервис дополнительно проверяет наличие лицензий у банка и наличие ограничений в его деятельности. Это позволяет удостовериться, что банковский платёж безопасен.
Более подробно ознакомиться с функциями подсказок по банкам можно на странице Демо сервиса, а также в документации к API подсказок по банкам и API получения сведений о банке.
 Кроме стандартизации и исправления почтовых адресов Ахантер позволяет получать разнообразную дополнительную информацию о каждом адресе. К таким сведениям относятся координаты, часовой пояс, ближайшие станции метро, а также справочные коды, присвоенные адресу по различным классификаторам, такие например, как ОКАТО, ОКТМО, КЛАДР и ФИАС.
Кроме стандартизации и исправления почтовых адресов Ахантер позволяет получать разнообразную дополнительную информацию о каждом адресе. К таким сведениям относятся координаты, часовой пояс, ближайшие станции метро, а также справочные коды, присвоенные адресу по различным классификаторам, такие например, как ОКАТО, ОКТМО, КЛАДР и ФИАС.
В новой версии сервиса к этим справочникам мы добавили кадастровые номера, которые присваиваются объектам недвижимости Росреестром. Теперь Ахантер умеет определять кадастровый номер для квартиры, дома и земельного участка. В качестве источника информации о кадастровых номерах мы использовали Государственный адресный реестр (ГАР).
По нашим оценкам, на данный момент охват этих объектов в рамках ГАР составляет 82% для квартир, 81% для домов и сооружений и 58% для земельных участков. Суммарно это составляет примерно 78 миллионов объектов недвижимости, рассредоточенных примерно по 700 тысячам кадастровых кварталов.
Для компактного хранения этих сведений в базе сервиса, а также для обеспечения максимального быстродействия при работе с этой базой мы отдельно разработали механизм компрессии кадастровых номеров, позволяющий без потери информации сжимать эти данные примерно в 5 раз.
 Выполнили очередное масштабное обновление базы гео-кодера на Ахантере. В предыдущей версии Ахантер не поддерживал координаты для адресов Запорожской и Херсонской областей, а также для Донецкой и Луганской народных республик, поэтому в данной доработке основной упор был сделан на получении этих данных из открытых источников.
Выполнили очередное масштабное обновление базы гео-кодера на Ахантере. В предыдущей версии Ахантер не поддерживал координаты для адресов Запорожской и Херсонской областей, а также для Донецкой и Луганской народных республик, поэтому в данной доработке основной упор был сделан на получении этих данных из открытых источников.
В рамках этой работы мы выполнили адаптацию обучаемого ИИ-алгоритма, который отвечает у нас за извлечение адресных координат из картографических данных с учётом специфики адресного образования, принятого на этих территориях. Также для этого в данной работе нам пришлось нарастить обучающую базу до ~95 тыс. примеров. Это позволило минимизировать погрешность извлечения и распознавания адресных объектов на карте нашим обученным алгоритмом.
В общей сложности удалось покрыть координатами ~22 тыс. улиц в ~3 тысячах населённых пунктов, что составляет ~50% от всех улиц и ~80% всех населённых пунктов, находящихся на территории данных регионов. Суммарно выполненное обновление базы гео-кодера позволило увеличить на 10% количество всей координатной информации по сравнению с предыдущей версией сервиса.
Также, кроме координат в рамках данной доработки, мы собрали и обновили информацию о городских районах в городах на новых территориях, а также информацию о часовых зонах.
 До недавнего времени Ахантер умел определять географические координаты по адресу только для адресов России. Для этих целей мы используем обучаемый ИИ-алгоритм, позволяющий извлекать из открытой карты координаты объектов, образующих адреса. Этот алгоритм работает в связке с алгоритмами стандартизации и очистки адресов Ахантера.
До недавнего времени Ахантер умел определять географические координаты по адресу только для адресов России. Для этих целей мы используем обучаемый ИИ-алгоритм, позволяющий извлекать из открытой карты координаты объектов, образующих адреса. Этот алгоритм работает в связке с алгоритмами стандартизации и очистки адресов Ахантера.
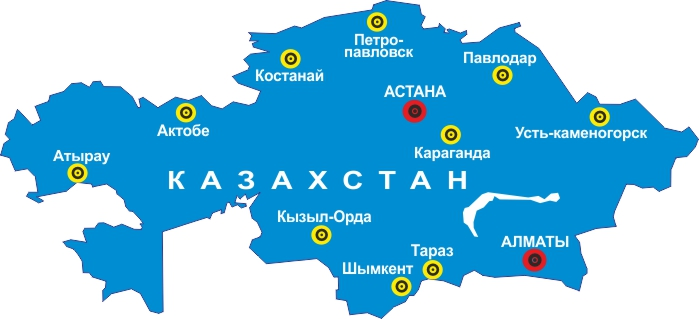
Поскольку ранее мы разработали и внедрили на Ахантере функции по стандартизации адресов Казахстана, то логичным продолжением этой разработки стало обучение гео-кодера, с помощью которого можно было бы по аналогии с адресами РФ собирать и пополнять координатную базу Казахстана. Для этих целей мы разработали новые инструменты для разметки данных и обучения гео-кодера, о чём сообщали ранее. Эти инструменты мы задействовали для настройки гео-кодера Казахстана.
В общей сложности было подготовлено ~90 тыс. обучающих примеров. Кроме этого в процессе разметки потребовалось немного доработать сами алгоритмы Ахантера, поскольку в адресах Казахстана встречается много специфики, не характерной для адресов России. Например, часто в улицах, названных в честь известных людей, фамилия и имя человека указывается не в родительном падеже, а в именительном (улица Максим Горький вместо улица Максима Горького). Также в Казахстане одно и то же название может отличаться по написанию из-за существования различных вариантов произношения. Для адресных данных на карте Казахстана такие ситуации встречаются довольно часто и, фактически, являются нормой, в отличие от адресов на карте России.
Все эти особенности были учтены при доработке и обучении гео-кодера на картографических данных Казахстана. После обработки карты Казахстана мы получили ~70% покрытие адресной базы координатами для улиц и домов городов. Более высокий процент на данный момент обеспечить сложно из-за неполноты самой OSM-карты Казахстана. Тем не менее, полученная база и соответствующий функционал гео-кодирования были внедрены на Ахантере и теперь можно получать не только стандартизированные адреса и подсказки для данной страны, но и координаты для них.
Гео-координаты для адресов Казахстана доступны во всех функциях API Ахантера, возвращающих стандартизованный адрес при указании страны принадлежности адреса country=kaz, а также при обработке адресов в пакетном режиме через личный кабинет.
26.09.2024 Внедрили подсказки по паспортным данным
20.07.2024 Обработали в облаке более 2 млрд. данных
09.04.2024 Добавили на Ахантере подсказки по реквизитам банков
01.02.2024 Внедрили кадастровые номера квартир, домов и участков
09.01.2024 Добавили координаты адресов для новых регионов
11.07.2023 Внедрили гео-кодер для адресов Казахстана
17.10.2022 Разработали новые ИИ-инструменты для обновления гео-кодера.
01.09.2022 Запустили на Ахантере сервис поиска по ФИАС-guid.
01.08.2022 Добавили проверку квартир в Ахантере при стандартизации адреса.
01.07.2022 Включили Ахантер в реестр отечественного ПО.
11.02.2022 Разработали новый язык правил извлечения из текстов.